Pairwise is making voting to distribute RetroPGF simple and fun. We are now pivoting to make signaling RetroPGF accessible to everyone in the Optimism Community! Pairwise is an open-source, off-chain voting dapp (like Snapshot) that streamlines community signaling by letting users select between just two options and then aggregating their choices into a quantifiable result. Pairwise is designed to be user-friendly and intuitive. Pairwise converts simple subjective inputs into objective, measurable outputs, minimizing the cost and cognitive burden of voting.

Pairwise real potential lies in aggregating data from various voters, allowing them to concentrate on areas where they have expertise. This means voters will spend more time in their areas of expertise.
This has incredible potential to increase project discovery and network effects within our community. This is why with this new version, we aim to give more community stakeholder groups the opportunity to participate in RetroPGF. We will amplify the voices of token holders, delegates, RetroPGF recipients, and badgeholders as community signaling.
Community Signaling as a Metric in Retro Funding 4
Retro Funding 4 is all about Metrics and one of the challenges on a heavy metrics result is that metrics can be manipulated and reductionist. Goodhart’s Law states: When a measure becomes a target, it ceases to be a good measure.
Dive deeper on this in this post from Owocki.
Furthermore, impact is more than TVL and number of unique transactions. Not every $100 transaction has the same impact. The impact of a project facilitating remittances would be considered by most to be more valuable than a meme coin, even if the onchain data says otherwise.
Pairwise  Retro Funding 4
Retro Funding 4
We are eager to put qualitative data onchain and give badgeholders the option to factor in community signaling as an onchain metric for Retro Funding 4 and we have a beautiful new version of our app to do it with!
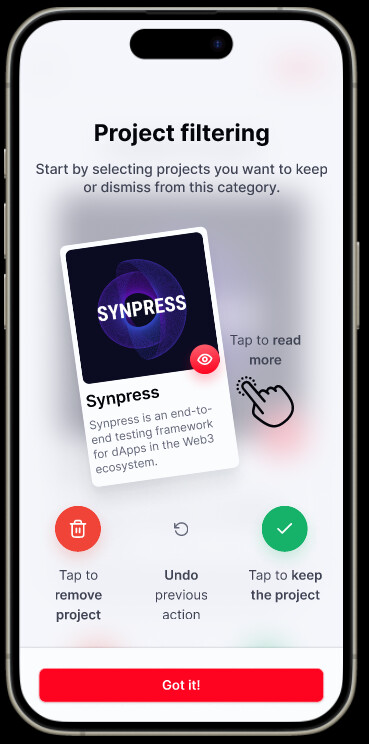
With Pairwise, the community can engage, discover, review, and rank the types of projects that interest them in Retro Funding 4. We will break the applicants into several categories which will contain 15-30 projects and the community will be able to rank the projects within each category, and then rank these categories as well. In this way, each voter can analyze just a portion of the projects and we can aggregate the results into one final ranking.
Pairwise WIP demo

Major V2 improvements:
- Mobile first
- Voter feedback
- Tinder-style filtering
- Sound effects & background music
- Pseudonymous account abstraction
Also the community will not allocate a number of tokens to each project, instead they only rank the projects using filtering and pairwise assessment. This greatly reduces the cognitive load of voting and gamifies the user experience.
The challenges to overcome are the tight timeline and engagement. We will launch a marketing campaign to maximize participation with rewards included from our RetroPGF 3 rewards!
Our proposal is to create four metrics, one for each of four stakeholder group; Badgeholders Rank, OP Hodlers Rank, Builders Rank & Delegates Rank. However we also could create 1 metric and give each stakeholder group 25% of the influence of an aggregated result if adding 4 metrics to the voting UI is seen as too much. Check voting power distribution below.
Voting power distribution
HOLDERS
- Link: Optimistic Etherscan Token Balances
- WHALE: 10M OP, 50 holders, Votes: 100
- Diamond: 1M OP, 190 holders, Votes: 50
- Platinum: 100k OP, 1000ish holders, Votes: 25
- Gold: 10k OP, Countless Holders, Votes: 10
- Silver: 1k OP, Countless Holders, Votes: 5
- Bronze: 500 OP, Countless Holders, Votes: 3
- Snapshot to be taken May 1st.
DELEGATES
- Link: Optimism Tally Delegates
- Diamond: 1M Delegated OP, 23 delegates, Votes: 8
- Platinum: 100k Delegated OP, 40 delegates, Votes: 5
- Gold: 15k Delegated OP, 64 delegates, Votes: 3
- Silver: 5k Delegated OP, 175 delegates, Votes: 2
- Bronze: 2.5k Delegated OP, 185 delegates, Votes: 1
- Snapshot to be taken June 18th.
BADGEHOLDERS
- 1 address 1 vote
- Retro Funding 4 Badgeholders on June 18th
RECIPIENT
- 1 address 1 vote
- Recipient projects in Retro Funding 4
Note: If a user holds multiple badges, they will be accounted for as Badgeholder, Delegate, or Recipient in that order. Everyone except delegates can also be accounted for as an OP holder. The reason for this is to protect user anonymity; otherwise, we could risk potential counter-engineering of anonymity.
Every one of those stakeholders will have a Pairwise ranking and those rankings will be aggregated. In order for for a bucket to provide relevant information to the collective we need:
- Badgeholders: 30 participating and at least 5 finalizing each category
- Recipients: 100 participating and 10 finalizing each category
- Delegates: 100 participating in Pairwise and 10 finalizing each category
- Holders: 400 participating and 20 finalizing each category
If one of the groups doesn’t meet the criteria, it will not be qualified to be a metric for voting in Retro Funding 4. At least 1 group needs to meet the minimum engagement requirements or no data will be added to the round.
Timing
The app will be ready for community signaling as soon as possible after projects are finalized. We propose to begin the signaling before the official vote begins and end a week before the voting has ended so that the final results are solidified for the last week of badgeholder voting.
Ranking Math
To determine the final rankings, we are debating three potential distributions that will be shared shortly in the comments below. Our goal is to gather feedback from the community on which distribution model will give the ideal distribution.
Reward Distribution for Pairwise Voting
The reward system is designed to promote stakeholder engagement. Pairwise is as fun as voting gets and we want to spice it up rewarding stakeholders signaling their preferences to the collective. We are allocating a total of 4,000 OP from our RetroPGF 3 Rewards, with 1,000 OP designated for each stakeholder group (Badgeholders, Recipients, Delegates, and Holders). Each participant’s chance of winning increases with more categories they vote in.
Raffle Tickets:
- For every 10 points earned, participants receive one raffle ticket.
- More tickets mean higher chances of winning.
How to Get Points::
- Category Participation: Finalizing the first category gives 10 points.
- Weighted Bonus Points (For Delegates and Hodlers bucket):
- Whale: +20 points per category
- Diamond: +15 points per category
- Platinum: +10 points per category
- Gold: +5 points per category
- Silver: +3 points per category
- Bronze: No additional points
- Max Tickets: 25% of the total number of categories. Once you have ranked 25% of the categories, you do not get extra points for ranking more.
Note that each stakeholder group has an equal total of 1,000 OP for distribution. A Holder may accumulate more points than a Badgeholder, but this will not affect the distribution among Badgeholders—it only enhances their chances within the Holder category.
At the end of the voting period, 10 winners will be randomly selected from the raffle tickets in each group. This ensures every participant has a chance to win, with active members enjoying improved odds thanks to their contributions to the collective. If a participant is both a Badgeholder and a Delegate, 1 vote will put them in both raffles!
Anti-Gaming Measures and Transparency
- The Pairwise voting process is not like snapshot, it will be very easy to track how users use the application using traditional analytics tooling to separate authentic users from bots and people who are just clicking through to promote their own projects.
- If the ballot submission looks like they are only farming the reward or just voting for their own projects without putting in an authentic effort to judge other projects, we will not give rewards to that voter, but we will still count the ballot. For the first round we will count every ballot even if we believe someone is farming the system for rewards.
- We will maintain complete transparency in the reward calculation and distribution process. Everything will be public.
Join us in Shaping the Future of Pairwise
We would love to hear your feedback and shape this experiment collectively. We’ve received massive support from the collective and want to continue evolving to suit the needs of the community to the best of our capacity. We’ve been working on this prototype that will internally launch on May 15.
You can share your comments here, or DM me at @Zeptimusq on Telegram, where we can go more in-depth and schedule a demo call.